Large Language Models (LLMs) like GPT and LLaMA are incredibly powerful — but also massive, often taking up hundreds of gigabytes!
In this short, I explain Quantization — a key optimization technique that makes these giant AI models faster, lighter, and efficient enough to run on laptops or even edge devices.
You’ll learn:
🔹 What quantization means in simple terms
🔹 How 32-bit weights become 8-bit or 4-bit without losing much accuracy
🔹 Why quantization is the reason behind faster, more accessible AI
🎓 Perfect for AI enthusiasts, data scientists, and anyone curious about how large models actually work under the hood!
#AI #MachineLearning #LLM #Quantization #TechExplained
source

Categories: OpenAI
Related Posts :-
-
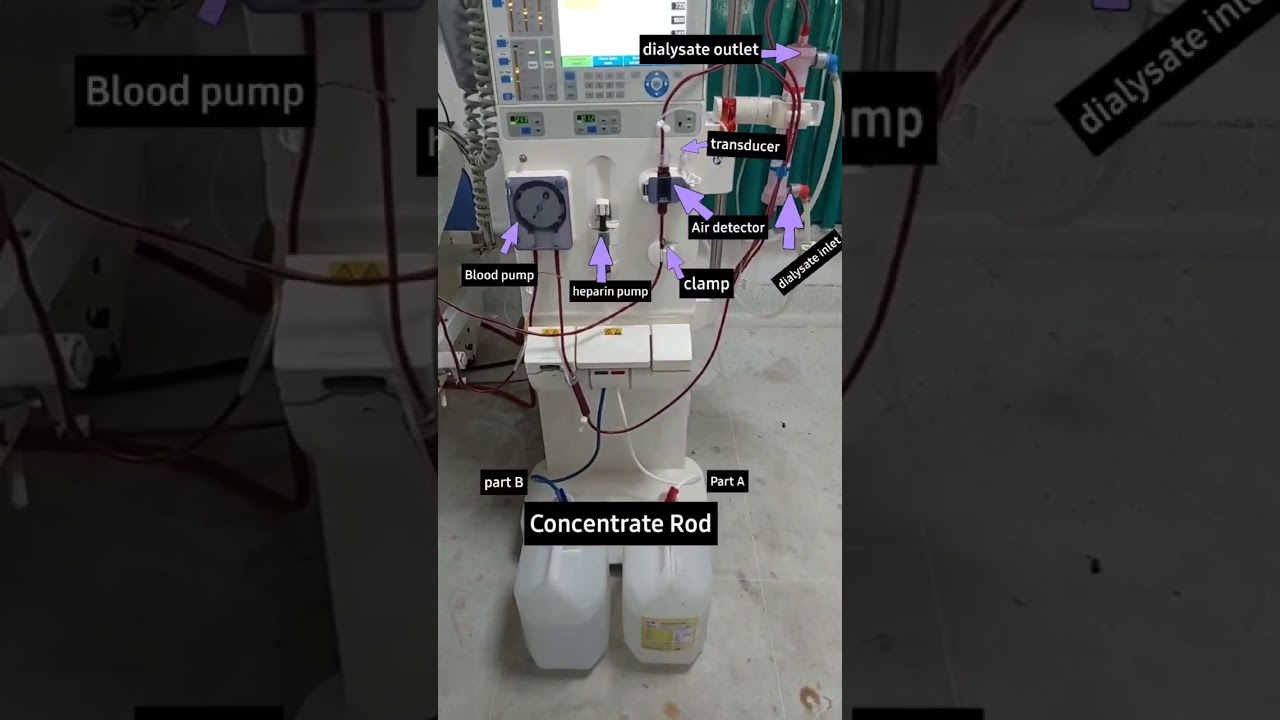
Parts of Dialysis machine #nephrologist #dialysis #dialysisstudy #viralshorts #kidney
Dialysis Study https://play.google.com/store/apps/details?id=dialysisstudy.learners.com Dialysis lecture 1. Dialysis Study: EXPERT NOTES…
-

Get Free Google & Microsoft Swags in 2026 | 5 Official Programs Explained
Want to get FREE Google and Microsoft swags, certificates, badges,…
-

police 😀 22Age Gemini prompt 👇 #gemini #ai #viral #army #police #photoediting #indianarmy #trending
“A young handsome Indian man, around 25-30 years old, with…