Ever wonder why AI agents are great for five minutes but forget everything by tomorrow? 🐟 It’s time to move past the “goldfish memory” era! In this episode, we explore the revolutionary LLM Wiki v2—a massive upgrade to Andrej Karpathy’s original vision, built for production-scale AI memory. 🧠✨
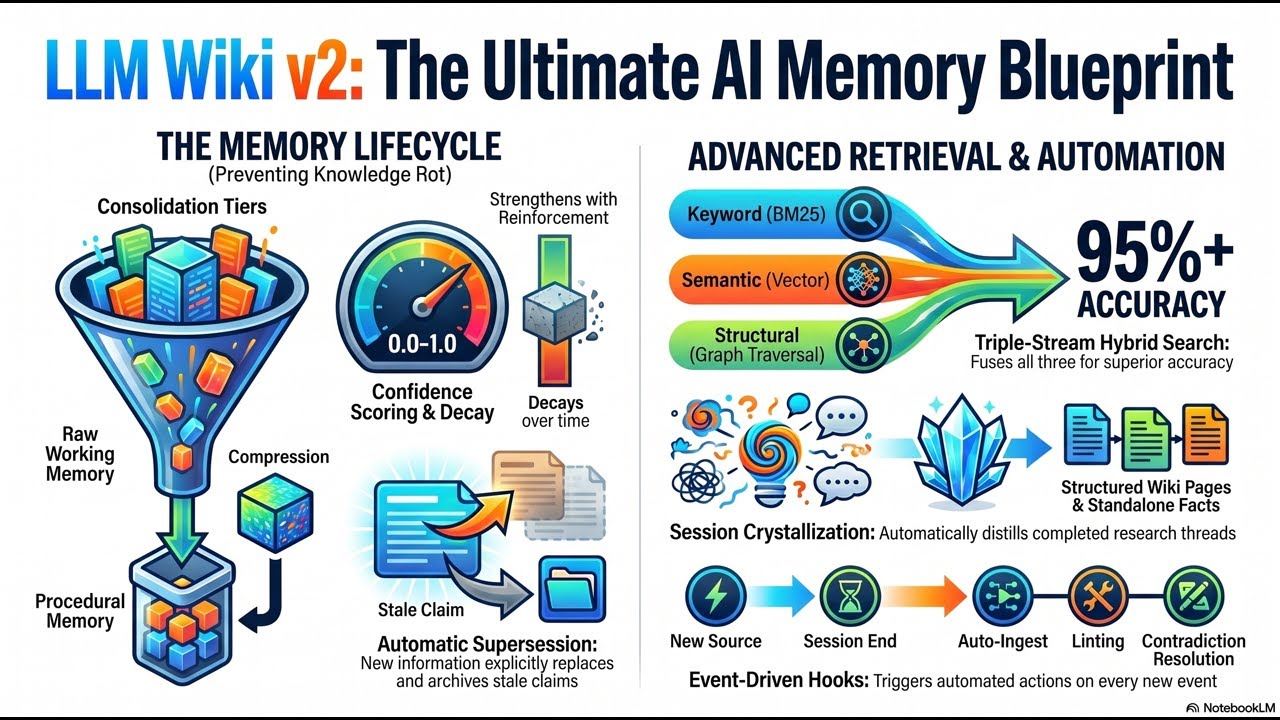
We dive into the “memory lifecycle” and why treating all data as equal leads to digital rot. Learn how confidence scoring, supersession, and Ebbinghaus-inspired forgetting curves keep your AI’s knowledge base sharp and relevant. 📉 We also break down the shift from flat markdown pages to powerful typed knowledge graphs. Imagine your AI navigating relationships like “depends on” or “contradicts” to find exactly what it needs! 🕸️
Scaling to thousands of pages? We’ve got you covered with Hybrid Search! Discover how combining BM25 keyword matching, vector embeddings, and graph traversal creates a search engine that actually understands context. 📚 We also talk about “crystallization”—the art of turning raw sessions into high-value structured facts automatically. 🤖🧪
Whether you’re a developer building the next autonomous agent or a productivity nerd looking for the ultimate digital brain, this episode is your blueprint for the future of associative intelligence. Let’s stop re-deriving and start compiling! 🚀🌍
Source: “LLM Wiki v2 — extending Karpathy’s LLM Wiki pattern with lessons from building agentmemory” by rohitg00 via GitHub Gists.
#AI #LLM #ArtificialIntelligence #MachineLearning #AgenticAI #Karpathy #KnowledgeManagement #VectorSearch #CodingAgents #SecondBrain
source
Categories: OpenAI
Related Posts :-
-
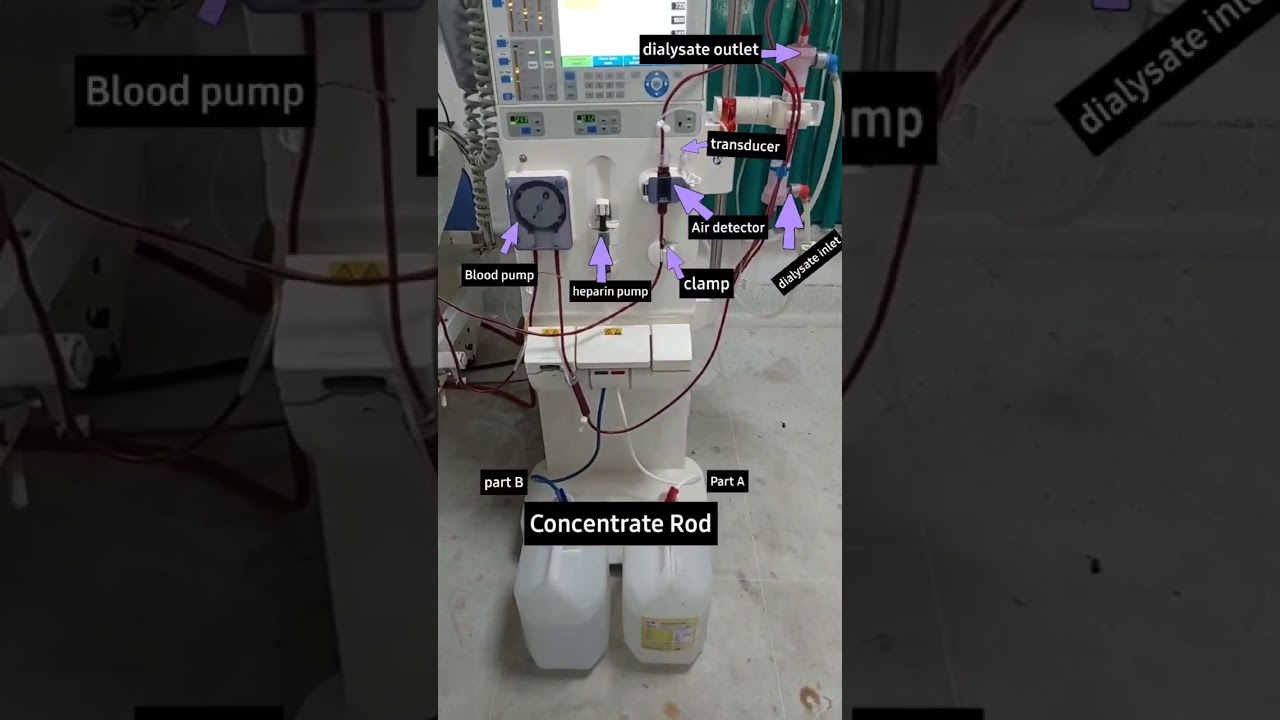
Parts of Dialysis machine #nephrologist #dialysis #dialysisstudy #viralshorts #kidney
Dialysis Study https://play.google.com/store/apps/details?id=dialysisstudy.learners.com Dialysis lecture 1. Dialysis Study: EXPERT NOTES…
-

Get Free Google & Microsoft Swags in 2026 | 5 Official Programs Explained
Want to get FREE Google and Microsoft swags, certificates, badges,…
-

police 😀 22Age Gemini prompt 👇 #gemini #ai #viral #army #police #photoediting #indianarmy #trending
“A young handsome Indian man, around 25-30 years old, with…